728x90
들어가며
- 사람은 소리를 들으면 곧잘 단어를 알아듣고, 다시 소리를 낼 수 있습니다.
- 그런데 컴퓨터에게 “소리를 듣고 글자로 바꿔라(STT)”, 혹은 “글자를 읽고 자연스럽게 말해라(TTS)” 라고 하면, 이게 생각보다 엄청 복잡한 일입니다.
- 그 이유는 소리 신호가 시간에 따라 계속 변하고, 말소리는 단순한 신호가 아니기 때문이죠.
- 오늘은 AI 음향 모델이 소리를 어떻게 이해하고 처리하는지, 대표적인 기술들과 함께 쉽게 설명해보겠습니다.
왜 음향 모델이 필요한가?
- 소리는 파도와 같다.
→ 소리는 파형(waveform). 하지만 AI는 “이 파형이 무슨 글자인지” 모르죠. - 음향모델은 이 파형 속에서 ‘발음 단위(phoneme)’ 라는 기본 단위로 신호를 쪼개고 분석합니다.
- 예: “she” → /sh/ + /iy/
- 즉 음향모델은 파형 → 음소 → 단어 로 가는 다리 역할을 합니다.
MFCC: 소리의 DNA 뽑아내기
- 사람이 목소리를 구별하듯, AI도 소리의 ‘특징’을 뽑아야 합니다.
- 여기서 등장하는 게 MFCC(Mel-Frequency Cepstral Coefficients).
- 비유: 소리를 “색깔 스펙트럼”으로 나누어 특징 벡터로 만드는 것.
- 음성 신호 → 작은 시간 단위로 자르기 → 스펙트럼 뽑기 → 로그와 DCT로 변환 → MFCC 벡터 추출.
GMM (Gaussian Mixture Model)
- MFCC 벡터를 보고 이게 어떤 소리일지 확률적으로 판단하는 모델.
- 비유: 여러 개의 종(鐘)을 울려보고 “지금 울린 소리는 어느 종 소리랑 가장 비슷한가?”를 확률로 따지는 것.
- GMM은 “이 소리가 어느 음소에 속할 확률”을 계산합니다.
- 수식적으로 각 feature vector는 여러 Gaussian 분포의 혼합으로 모델링.
HMM (Hidden Markov Model)
- GMM이 “순간”을 잘 본다면, HMM은 “흐름”을 본다.
- 말은 이어지기 때문에, 앞 음소가 뭐였느냐가 다음 음소에 영향을 미침.
- HMM은 숨겨진 상태(음소) → 관찰값(MFCC) 의 관계를 모델링.
- 비유: 문장 읽기 게임 → 눈으로 본 글자(관찰값)는 보이지만, 머릿속 생각(숨겨진 상태)은 안 보이는 것과 같음.
- HMM은 상태 전이 확률, 방출 확률로 음성 시퀀스를 모델링.
GMM-HMM의 결합
- GMM + HMM → 음향모델의 전통적 조합.
- GMM은 각 프레임의 음소 분포를 계산.
- HMM은 음소들의 시퀀스를 모델링.
- 비유: GMM은 단일 사진을 분석, HMM은 사진들을 이어붙여 영화로 보는 것.
하이브리드 모델 (DNN-HMM, LSTM-HMM)
- GMM-HMM보다 더 똑똑한 게 필요해졌다!
- GMM은 선형적 가정, 단순한 분포라 한계가 있음.
- 그래서 GMM 대신 DNN, LSTM을 쓰기 시작:
- DNN-HMM: GMM 대신 DNN이 분포를 학습
- LSTM-HMM: 시간 흐름을 더 잘 기억
- 비유: GMM은 수학적 공식으로만 소리를 구분, DNN은 소리를 보고 “느낌적으로” 구분 가능.
Viterbi 디코더
- HMM-HMM 또는 Hybrid Model의 필수 도구.
- 가장 높은 확률의 음소 시퀀스(숨겨진 상태)를 찾아내는 알고리즘.
- 비유: 미로에서 가장 가능성 높은 길을 찾는 네비게이션.
최근 트렌드
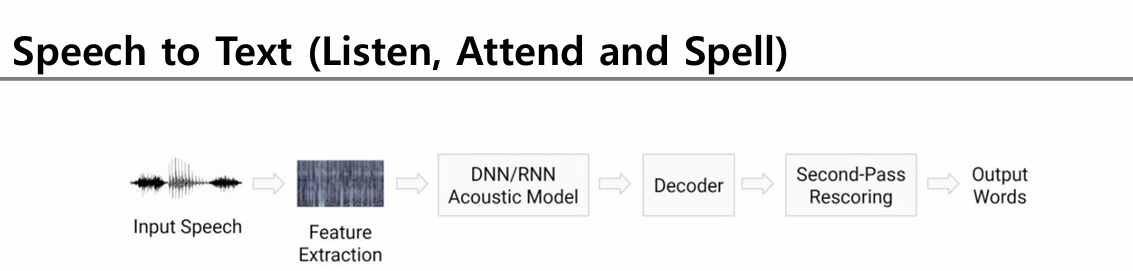
- Deep Learning으로 Acoustic Model 완전 대체 → End-to-End 모델(LAS, CTC)도 뜨고 있음.
- 하지만 Hybrid Model도 여전히 많이 쓰인다 (실제 상용 STT 엔진들).
정리
- 소리의 파동 → MFCC
- MFCC → GMM 혹은 DNN으로 분류
- 시간 흐름 → HMM
- HMM + GMM = GMM-HMM
- GMM 대신 DNN/LSTM → 하이브리드 모델
- End-to-End 모델(LAS, Transformer 등)로도 발전 중
✅ 이해를 돕는 비유 정리
| 개념 | 비유 |
| MFCC | 색깔 스펙트럼 뽑아내듯 소리의 특징 벡터화 |
| GMM | 여러 종 소리와 비교해 비슷한 종 찾기 |
| HMM | 글자 읽기 게임 – 머릿속 생각은 안 보인다 |
| Viterbi | 미로에서 가장 가능성 높은 길 찾기 |
| Hybrid Model | 수학 대신 ‘느낌적 판단’을 배우는 AI |
728x90
'인공지능 & 데이터 사이언스 > AI 기초 개념과 발전 역사' 카테고리의 다른 글
| AI는 어렵다?" 딥러닝 입문, 코랩 하나면 끝! (3) | 2025.06.09 |
|---|---|
| AI부터 자율제조까지, 인공지능 기술 총정리 (1) | 2025.06.09 |